Using Faster R-CNN with Resnet V2 for Object Detection with OptimEyes Developer

An object detection model that returns the coordinates and object class of objects indentified in an image.
Model Homepage & Information
- Model information and download
- Object category labels
- Demo video - how to use this ML model in a VisualEyes Script
Basic ML Tool Settings
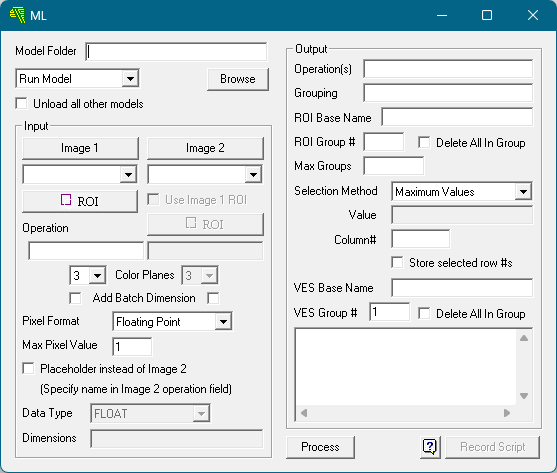
The following information is valid for the version of the model that we downloaded, and may vary if different versions of the model are published.
- Inputs: this model takes a single input image*1, indicated by the Image 1 field.
- Input Operation Name: serving_default_input_tensor
- Input Image Format: 3 color planes, add batch dimension (checked,) integer pixel format, max pixel value 255
- Output Operations: list any of the following that you wish to use:
- StatefulPartitionedCall:0: "detection_anchor_indices", the anchor indices of the detections after NMS. Without having investigated further, our guess is that these numbers can be used to associate the "raw" detection boxes and scores with the final boxes and scores. If you need these values, you probably know what to do with them.
- StatefulPartitionedCall:1: "detection_boxes", four numbers, which are the coordinates of two corners of a box surrounding an object that has been identified. Coordinates for each corner point are in Y, X order. Numbers range from 0 to 1, so to obtain image coordinates, it is neccessary to multiply by the height or width respectively of the input image or ROI. (This is done automatically when using the Grouping specifier "Ryxd".)
- StatefulPartitionedCall:2: "detection_classes", integers corresponding to object classes in the COCO 2017 dataset. The numbers correspond to the line numbers in the original list from the COCO paper (ie. use the file "coco-labels-paper.txt" at the link above.)
- StatefulPartitionedCall:3: "raw_detection_scores" or "detection_multiclass_scores", the other being StatefulPartitionedCall:7. We are unsure which is which. Either way, if you simply want to locate and identify the most likely classes of objects, you won't need these values. If you actually need them, then you can probably figure out which is which.
- StatefulPartitionedCall:4: "detection_scores", decimal numbers ranging from 0 to 1 indicating the confidence level that the object has been accurately identified.
- StatefulPartitionedCall:5: "num_detections", the number of objects detected -- this output only appears in the first row.
- StatefulPartitionedCall:6: "raw_detection_boxes", ROI coordinates for detection boxes without Non-Max suppression (you likely will use the "detection boxes" field instead of this.)
- StatefulPartitionedCall:7: see StatefulPartitionedCall:3
- Output Grouping: You can use "*" to autodetect all outputs. If you wish to automatically generate ROI rectangles for the detection boxes, use the setting "Ryxd" (generate Rectange ROIs, coordinates in Y, X order, scaled to the Dimensions of the input image or ROI.)
Example Output Operations and Grouping settings:
- Operation(s): StatefulPartitionedCall:1, StatefulPartitionedCall:2 ,StatefulPartitionedCall:4
- Grouping: Ryxd,*,*
With these settings, you will probably want to use Column# 3 (the detection scores) for selection based on Maximum Values or values Greater Than some threshold Value such as 0.7.
Notes:
- Many ML models, including this one accept batches of input images. When we say that it accepts a single input, what we mean is that each input image is processed independently, so only the "Image 1" field should be used. Because this model accepts batches of images, the "Add Batch Dimension" checkbox needs to be checked, as indicated above.